1. 前言
了解蓝牙的人都知道,在经典蓝牙中,保持连接(Connection)是一个相当消耗资源(power和带宽)的过程。特别是当没有数据传输的时候,所消耗的资源完全被浪费了。因而,对很多蓝牙设备来说(特别是功耗敏感的设备),希望在无数可传的时候,能够断开连接。但是,由于跳频(hopping)以及物理通道(Physical Channel)划分的缘故,经典蓝牙连接建立的速度实在难以忍受(要好几秒)。对那些突发的数据传输来说,几秒钟的连接延迟,简直是灾难。
因此,蓝牙SIG制订BLE规范的时候,充分考虑了这方面的需求,极大的简化了连接的建立过程,使连接速度可以达到毫秒级(最快3.75ms就可以搞定)。与此同时,为了节省功耗,也调整了跳频的策略。至此,相比广播通信而言,BLE面向连接的通信,几乎没有额外的代价。
在“蓝牙协议分析(5)_BLE广播通信相关的技术分析”中,我们对BLE的广播通信有了比较全面的了解,本文将接着分析和面向连接的通信有关的技术,包括连接的建立和断开、BLE跳频(Hopping)技术、Link Layer的应答、重传、流控、等等。
2. 怎样才算是建立了连接?
开始之前,我们先回答一个问题,对通信的双方而言,怎样才算建立了连接呢?
从字面上理解,建立了连接,就是指:
二者之间,建立了一条专用的通道,它们可以随时随地的通信。
当然,在蓝牙这种资源有限的通信系统中,通道无法独占,退而求其次,分时也Okay。因此,在BLE中建立了连接,是这样定义的:
在约定的时间段内,双方都到一个指定的物理Channel上通信。
其中,“约定好的时间段”,是时分的概念。而“到指定的物理Channel上”,是跳频的概念。后面的分析,将会围绕这两个概念进行。
另外,和“蓝牙协议分析(5)_BLE广播通信相关的技术分析”类似,我们也将从Link Layer、HCI、GAP三个层次,分别介绍。
3. Link Layer
3.1 角色的定义
和经典蓝牙一样,协议为处于连接状态的BLE设备,定义了两种Link Layer角色:Master和Slave。Master是连接的发起方(Initiator),可以决定和连接有关的参数(很重要,后面会详细介绍)。Slave是连接的接受方(Advertiser),可以请求(或建议)连接参数,但无法决定。
注1:两个BLE设备之间,只能建立一条连接。
3.2 PDU的定义
和广播通信不同,面向连接的通信使用特定的PDU,称作Data Channel PDU,格式如下(LSB---->MSB):
|
Header(16 bits)
|
Payload(Variable size)
|
MIC(32 bits)
|
16bits的Header的格式如下:
|
LLID(2 bits)
|
NESN (1bit)
|
SN(1 bit)
|
MD(1 bit)
|
RFU(3 bits)
|
Length(8 bits)
|
Data Channel传输的PDU有两类,一类是数据,称作LL Data PDU,另一类中控制信息,称作LL Control PDU。LLID用于区分PDU的类型,具体可参考后面3.2.1和3.2.2的描述。
NESN(Next Expected Sequence Number)和SN(Sequence Number),用于数据传输过程中的应答(Acknowledgement)和流控(Flow Control),具体可参考后面3.7的介绍。
MD(More Data),用于连接的关闭(或者说保持),具体可参考后面3.5的介绍。
RFU(Reserved for Future Use)。
Length,有效数据的长度(Payload+MIC),只有8-bits,因此Link Layer所能传输的最大数据是255 bytes(有MIC的话是251bytes),如果L2CAP需要传输更多的数据,需要分包之后传输(这也是L2CAP的主要功能之一,具体可参考“蓝牙协议分析(3)_蓝牙低功耗(BLE)协议栈介绍”)。
Payload是有效数据(SDU,L2CAP的PDU),长度由Header中的Length字段觉得,有效范围是0~255。
3.2.1 LL Data PDU
LL Data PDU有两种:
Header中的LLID=01b时,Continuation fragment of an L2CAP message, or an Empty PDU。这种类型的PDU,要么是一个未传输完成L2CAP message(长度超过255,被拆包,此时不是第一个),要么是一个空包(Header中的Length为0)。
Header中的LLID=01b时,Start of an L2CAP message or a complete L2CAP message with no fragmentation。这种类型的PDU,要么是L2CAP message的第一个包,要么是不需要拆包的完整的L2CAP message,无论哪种情况,Header中的Length均不能为0。
3.2.2 LL Control PDU
Header中的LLID=11b时,表示这个数据包是用于控制、管理LL连接的LL control PDU。LL control PDU的payload的格式如下:
|
Opcode(1 octet)
|
CtrlData(0 ~ 26 octets)
|
其中Opcode指示控制&管理packet的类型,包括:
LL_CONNECTION_UPDATE_REQ,连接参数的更新;
LL_CHANNEL_MAP_REQ,Channel map的更新;
LL_TERMINATE_IND,连接即将被关闭的通知(可以通知被关闭的原因);
LL_ENC_REQ、LL_ENC_RSP、LL_START_ENC_REQ、LL_START_ENC_RSP,加密有关的请求;等等,具体可参考“BLUETOOTH SPECIFICATION Version 4.2 [Vol 6, Part B]”。
3.3 连接的建立
对BLE来说,连接建立的过程很简单,包括:
1)处于connectable状态设备(Advertiser),按照一定的周期广播ADV_IND或者ADV_DIRECT_IND包(可参考“蓝牙协议分析(5)_BLE广播通信相关的技术分析”)。
2)主动连接的设备(Initiator),在收到广播包之后,会回应一个CONNECT_REQ请求,该请求携带了可决定后续“通信时序”的参数,例如双方在哪一个时间点、哪一个Physical Channel收发数据,等等,后面会详细描述。
3)Initiator在发出CONNECT_REQ数据包之后,自动转变为Connection状态,成为Master角色(注意:这是“自动”的,不需要等待另一方的回应)。同样,Advertiser在收到CONNECT_REQ请求之后,也自动转变为Connection状态,成为Slave角色。
4)此后,双方按照CONNECT_REQ参数所给出的约定,定时到切换到某一个Physical Channel上,按照Master->Slave然后Slave->Master的顺序,收发数据,直至连接断开。
master在发出连接请求的时候,需要在CONNECT_REQ PDU的payload中,定义和连接有关的参数。payload的格式如下:
|
InitA (6 octets)
|
AdvA (6 octets)
|
LL Data (22 octets)
|
其中InitA和AdvA分别是Master和Slave的蓝牙地址,LL data则包含了所有的连接参数,包括:
AA
(4 octets)
|
CRCInit
(3 octets)
|
WinSize
(1 octet)
|
WinOffset
(2 octets)
|
Interval
(2 octets)
|
Latency
(2 octets)
|
Timeout
(2 octets)
|
ChM
(5 octets)
|
Hop
(5 bits)
|
SCA
(3 bits)
|
AA,LL Connection的Access Address,在不同设备组合之间,需要唯一,并遵守一些原则,具体可参考“BLUETOOTH SPECIFICATION Version 4.2 [Vol 6, Part B]”。
CRCInit,用于CRC计算的一个初始值,由Link Layer随机生成。
WinSize和WinOffset,全称是transmitWindowSize和transmitWindowOffset,用于决定连接双方收发数据的时间窗口(第2章提到的时分的概念)。下面3.4小节会详细介绍。
connInterval,全称是connInterval,连接双方收发数据的周期。由于一个Master可能会和多个Slave建立连接,因此蓝牙的信道资源不能被某一个LL Connection所独占,所以一个收发周期中,可能有多个连接进行收发数据(具体的时间窗口,由transmitWindowOffset决定)。下面3.4小节会详细介绍。
Latency和Timeout,全称是connSlaveLatency和connSupervisionTimeout,和连接超时、自动断开有关,具体可参考3.4小节的描述。
ChM的全称是Channel map,用于标识当前使用和未使用的Physical Channel。Hop的全称是hopIncrement,它和ChM一起决定了数据传输过程中的跳频算法,具体可参考3.6小节的描述。
SCA(sleep clock accuracy),用于定义最差的Master睡眠时钟精度,具体可参考“BLUETOOTH SPECIFICATION Version 4.2 [Vol 6, Part B]”,本文不再详细介绍。
3.4 连接建立后的通信过程
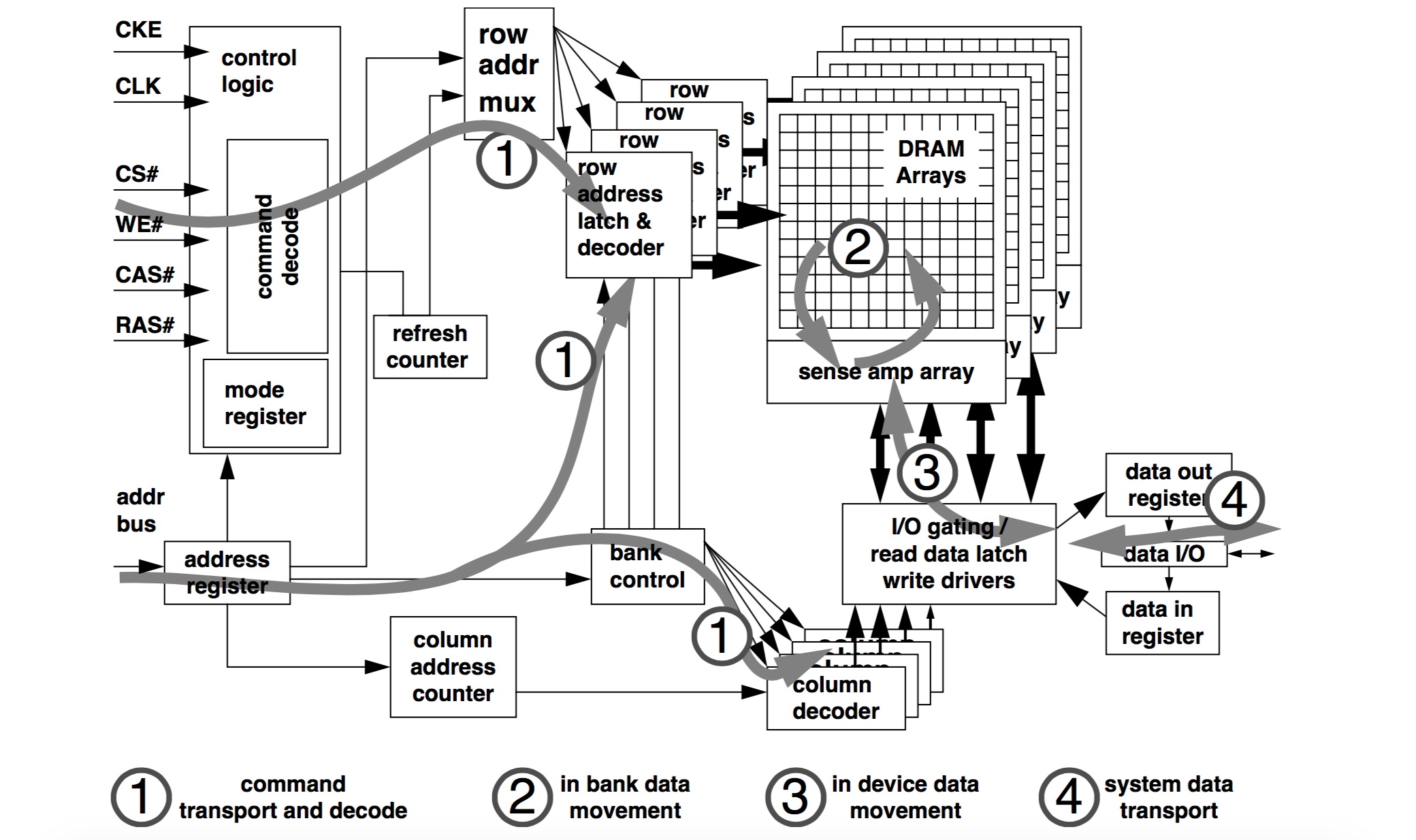
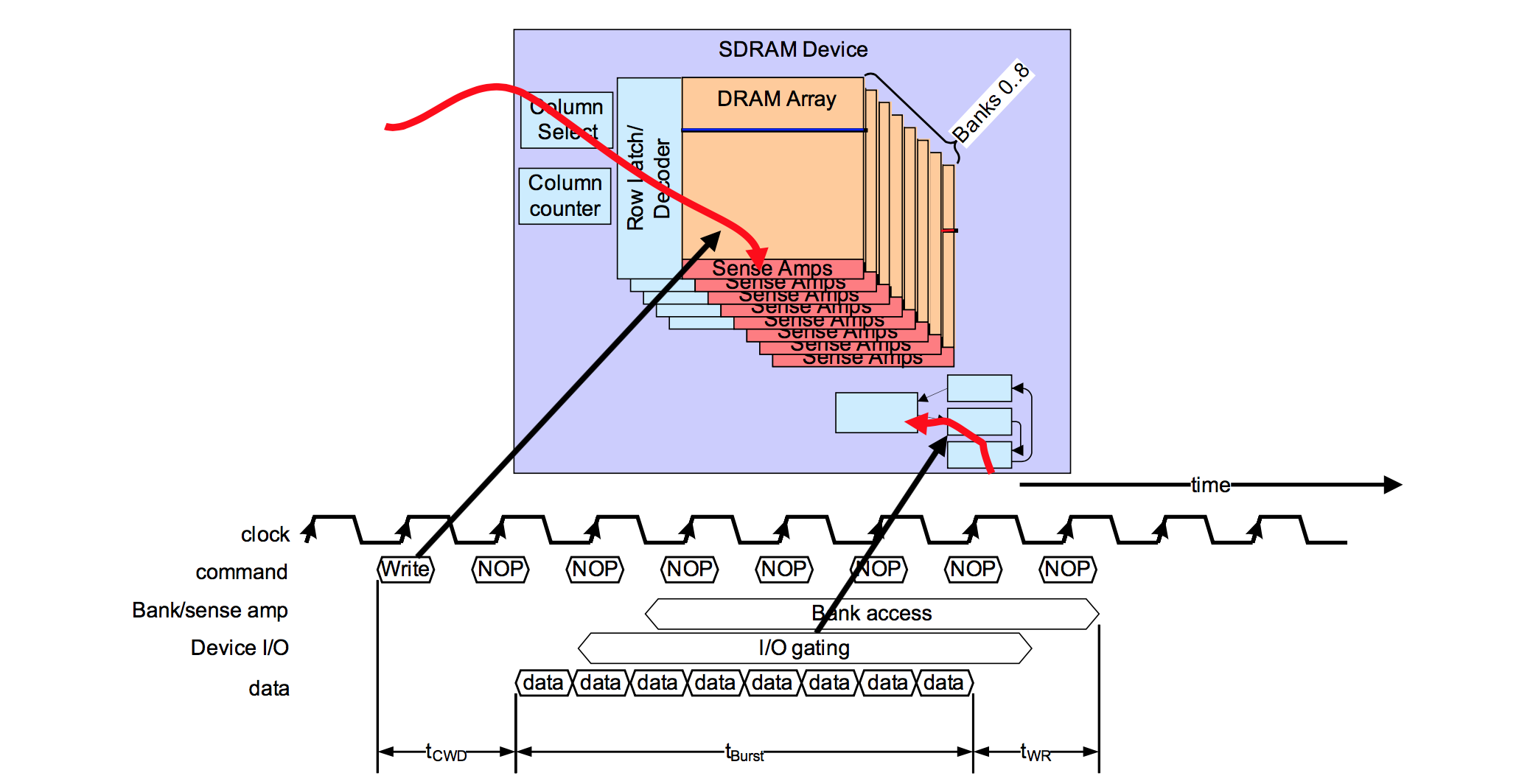
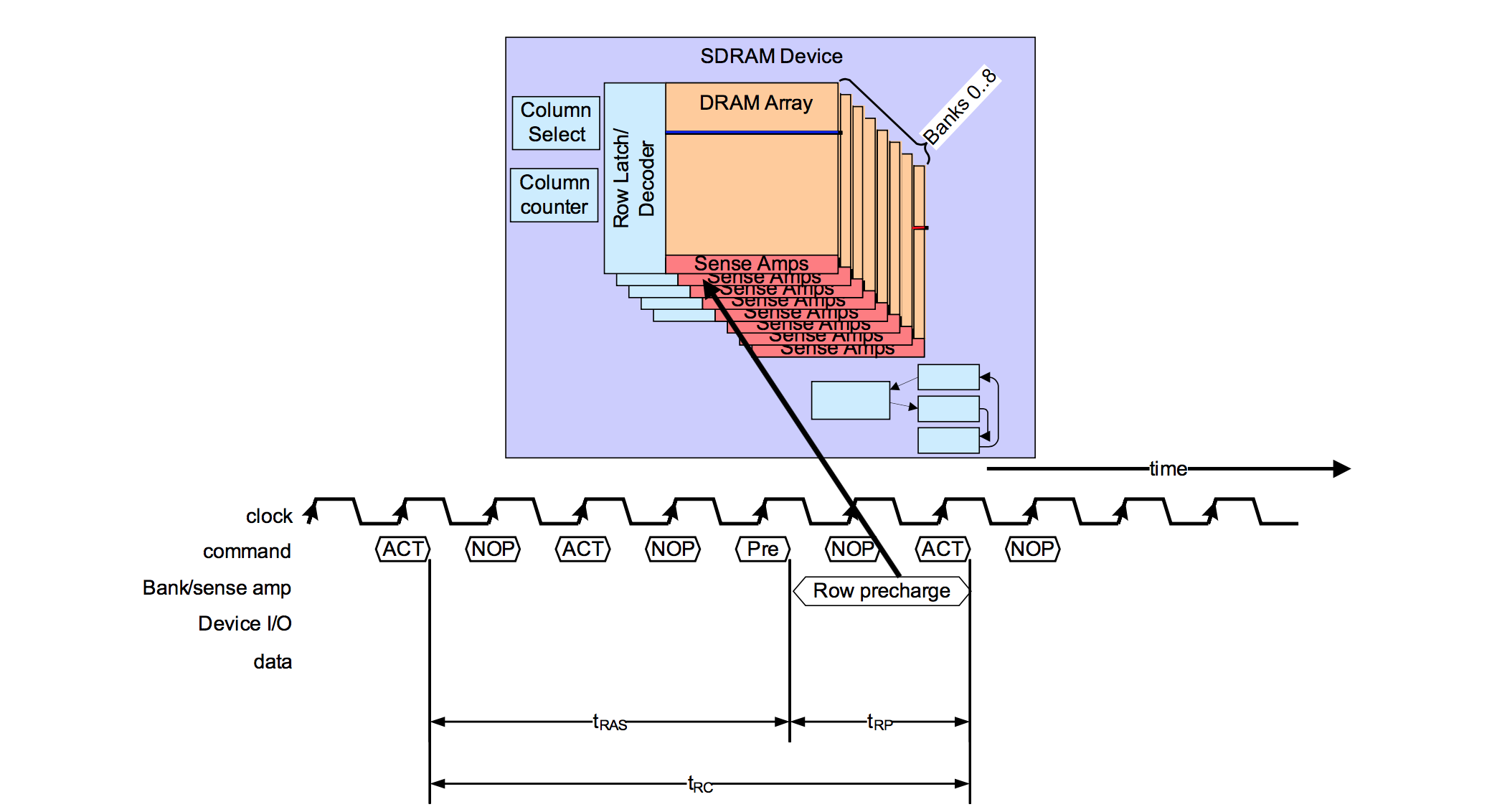
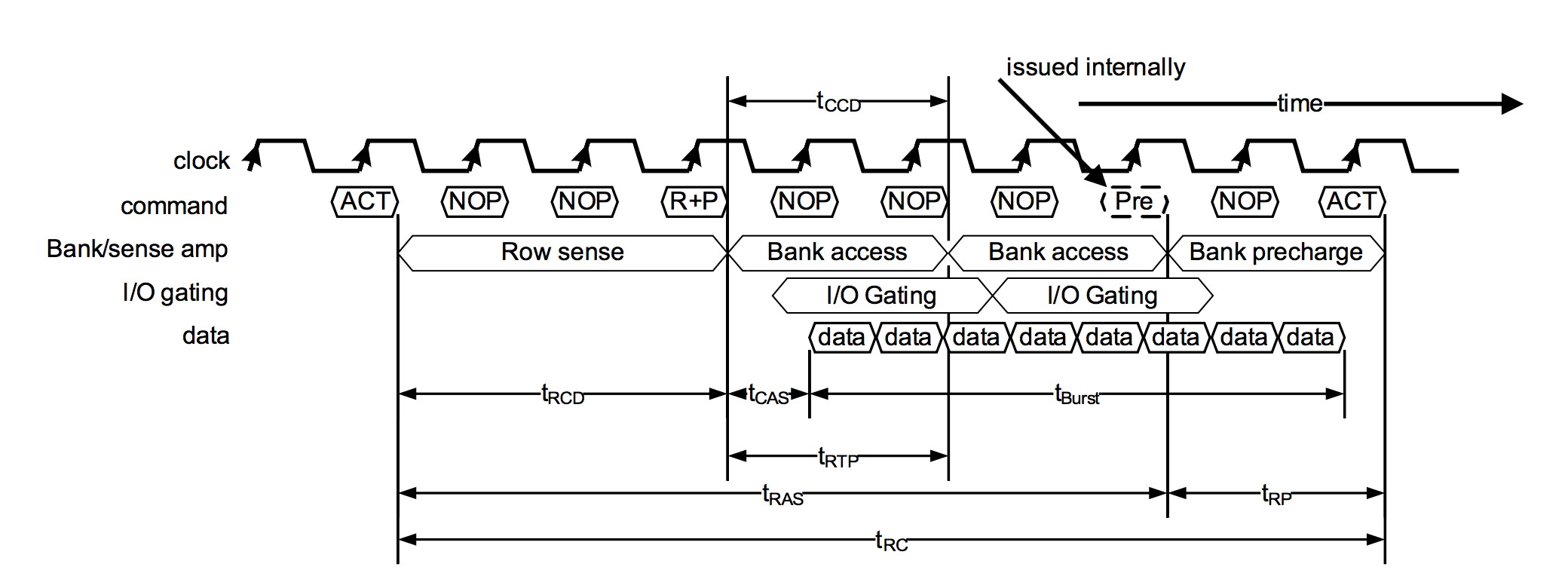
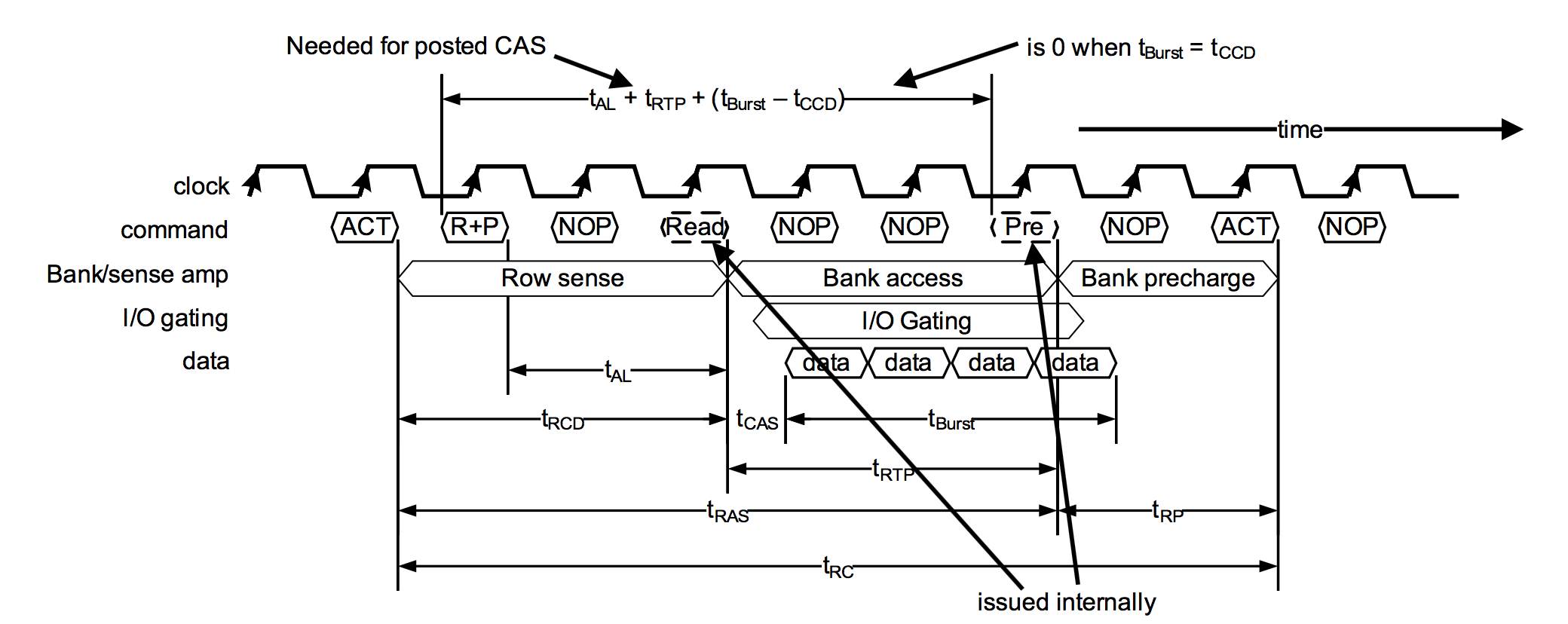
3.3小节提到,当Master发出/Slave收到CONNECT_REQ后,就自动进入连接状态,那双方在收发数据的时间窗口怎么确定呢?可参考下面图片1和图片2:

图片1 BLE连接时序---Master视角

图片2 BLE连接时序---Slave视角
1)从Master的视角看,当它发出CONNECT_REQ后,会在1.25 ms + transmitWindowOffset到1.25ms + transmitWindowOffset + transmitWindowSize之间,发送第一个packet(M->S)。同理,Slave在收到CONNECT_REQ之后,也会在相应的时间区间去接收packet(M->S)。
a)transmitWindowOffset可以控制这个LL Connection使用哪一段时间进行通信,从而保证了同一个Master和多个Slave之间的多个连接,可以互不影响的通信(时分)。transmitWindowOffset的取值范围是:0 ms到connInterval(后面会介绍connInterval)。
b)从Master发出CONNECT_REQ,到Slave接收到CONNECT_REQ,是有一定的时间延迟的,因此需要一定的时间窗口(transmitWindowSize),才能保证第一个packet能否正确的发送并被接收。transmitWindowSize必须是1.25ms的倍数,最小值是1.25 ms,最大值是(connInterval - 1.25 ms),但不能超过10ms。
c)正常情况下,所有“M->S”数据包的发送,不能超过transmitWindowSize,以便留出S->M的时间。但第一个packet例外(参考上面图片1)。
2)Master发出第一个packet之后,将以此为起始点(称作anchor point),以connInterval为周期,接着发送后续的packet(M->S),以及接收Slave的packet(S->M),具体可参考上面图片1。
a)这样以connInterval为周期的发送(M->S)、接收(S->M)组合(可能有多个),称作Connection Event。因此BLE面向连接的通信的基础,就是Connection Event。
b)connInterval的大小,决定了数据传输的周期。对一个连接来说,每个周期只能有一次的收发,因此connInterval的选择,直接决定了数据传输的速度。BLE协议规定,connInterval必须是1.25ms的倍数,范围是7.5ms~4s。
3)Slave如果没有收到第一个packet(M->S),则会以1.25 ms + transmitWindowOffset为起点,等待connInterval之后,再次尝试接收,直到接收到为止。Slave接收到packet之后,则以收到该packet的时间点为起始点(anchor point),以connInterval为周期,接着接收后续的packet(M->S),以及发送packet给Master(S->M),具体可参考上面图片2。
注2,关于数据传输的速率:
由上面的通信过程可知,BLE面向连接的通信速率,是由connInterval以及每个Connection Event中所传输的数据量决定的。
由上面3.2的描述可知,LL Data PDU的有效负荷不能超过255(251)bytes,不过考虑到一次传输的效率、错误处理等因素,具体的Link Layer不会使用这么大的packet。相应地,为了提高传输速度,一般会在一个Connection Event中,传输多个packet。以iOS为例,它可能会在一个Connection Event中,传输6个packets,每个packet的长度是20bytes。
另外,很多平台为了保证自身作为Master的性能,会限制connInterval的最小值,以iOS为例,最小值是30ms。因此,可估算得到相应的传输速率为20B * 6 / 30ms = 32kbps,是相当缓慢的。
注3:BLE的面向连接通信是使用跳频技术的,即每次Connection Event,都会使用不同Physical Channel收发数据,具体的跳频机制,可参考3.6小节的介绍。
3.5 连接的控制与管理
连接建立之后,Master或者Slave可以借助Link Layer Control Protocol (LLCP),通过LL Control PDU,对连接进行管理控制,包括:
Connection Update Procedure,连接参数(包括connInterval,connSlaveLatency,connSupervisionTimeout)更新的通知。只能由Master发起。
Channel Map Update Procedure,更新Channel map。只能由Master发起。
Encryption Procedure,对连接进行加密,可由master或者slave发起。
Termination Procedure,断开连接。
Connection Parameters Request Procedure,请求更新连接参数(connInterval,connSlaveLatency,connSupervisionTimeout),Slave或者Master都可以发起,和Connection Update Procedure不同是,这是一个协商的过程,不是一定能够成功。
LE Ping Procedure,类似于网络协议中ping操作。
等等。不再详细介绍,具体可参考“BLUETOOTH SPECIFICATION Version 4.2 [Vol 6, Part B]”。
3.6 连接超时及断开
BLE连接断开的原因有两种:一种是预期内的、主动断开,此时会走3.4小节提到的Termination Procedure过程;第二种是一些非预期的原因导致的超时断开,如距离超出、遭受严重的干扰、突然断电等。
对于第一种,是协议内的正常流程,没有什么好说的。而对于第二种,则需要一些timeout机制,检测这写异常情况,具体如下。
1)Master和Slave的Link Layer,都会启动一个名称为TLLconnSupervision的timer,每接收到一个有效的数据包时,该timer都会重置。
2)连接建立的过程中,如果TLLconnSupervision超过6 * connInterval(没有接收到第一个数据包),则认为连接建立失败。
3)在连接成功之后,如果TLLconnSupervision超过connSupervisionTimeout,则说明link loss,则执行超时断开。connSupervisionTimeout是一个可配置的参数,范围是100ms~32s,并且不能大于(1 + connSlaveLatency) * connInterval * 2。
4)BLE协议允许slave忽略掉“connSlaveLatency”个Connection Event,在被忽略的这段时间内,Slave不需要收发数据包,也不会增加TLLconnSupervision,从而引发超时断开。connSlaveLatency是一个整数,有效范围应该在0到((connSupervisionTimeout / (connInterval*2)) - 1)之间,并且不能大于500。
注4:connSlaveLatency是一个非常有用的参数,它允许Slave在数据通信不频繁的时候,忽略掉一些Connection Event,进而可以睡得更久,更加省电。
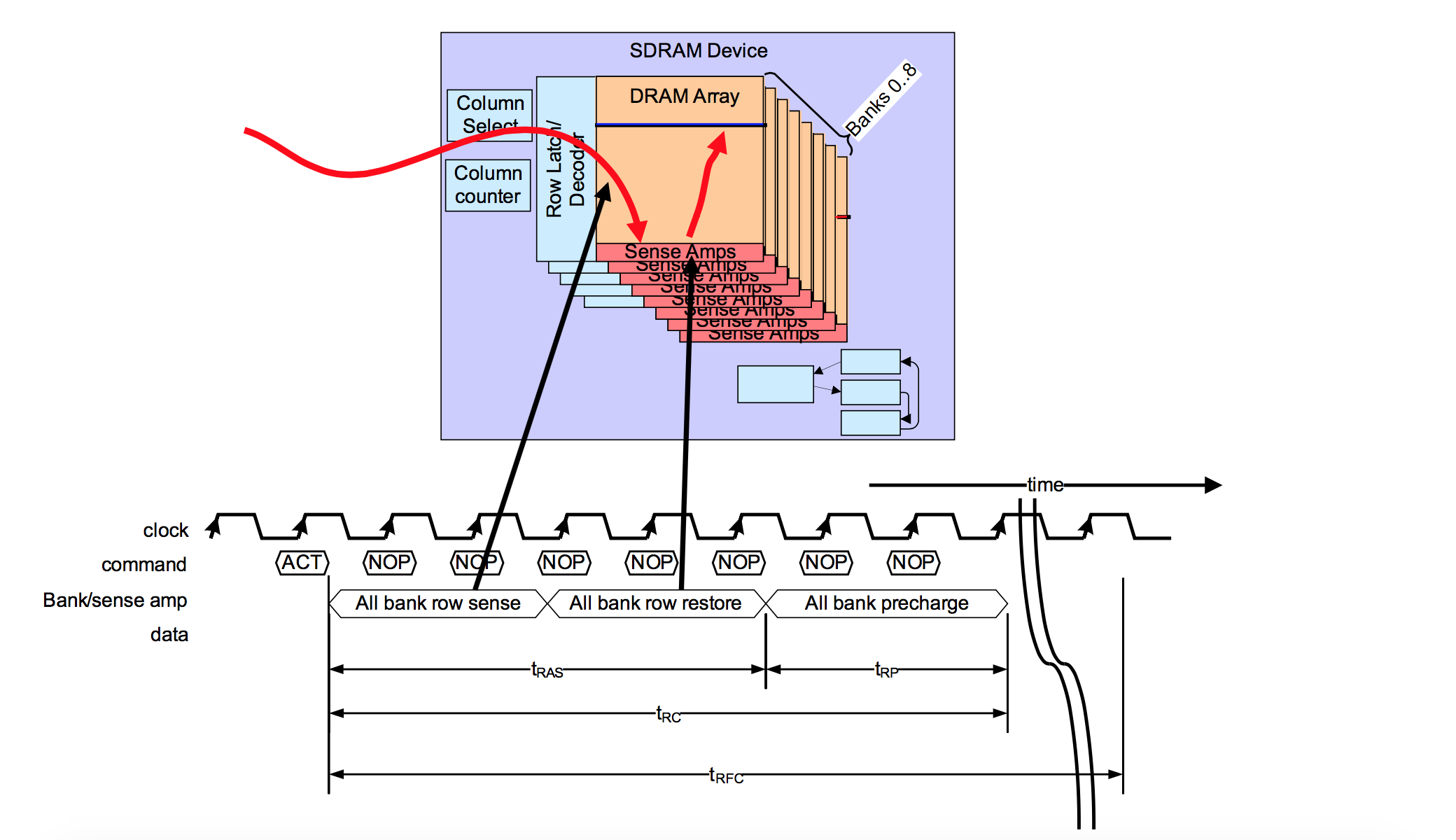
3.7 跳频(Hopping)策略
BLE的跳频策略是非常简单的,即:每一个Connection Event,更换一次Physical Channel,当然,master和slave需要按照相同的约定更换,不然就无法通信。这个约定如下:

图片3 BLE跳频策略
1)首先,使用一个Basic的算法,利用lastUnmappedChannel和hopIncrement,计算出unmappedChannel。
a)lastUnmappedChannel在连接建立之初的值是0,每一次Connection Event计算出新的unmappedChannel之后,会更新lastUnmappedChannel。
b)hopIncrement是由Master在连接建立时随机指定的,范围是5到16(可参考3.3中的Hop)。
c)确定unmappedChannel的算法为:unmappedChannel = (lastUnmappedChannel + hopIncrement) mod 37,本质上就是每隔“hopIncrement”个Channel取一次,相当直白和简单。
2)计算出unmappedChannel之后,查找当前的Channel map,检查unmappedChannel所代表的Channel是否为used channel。如果是,恭喜,找到了。
Channel map也是由master,在连接建立时,或者后来的Channel map update的时候指定的。
3)如果不是,将所有的used Channel以升序的方式见一个表,表的长度是numUsedChannels,用unmappedChannel和numUsedChannels做模运算,得到一个index,从按照该index,从表中取出对应的channel即可。
3.8 应答(Acknowledgement)和流控(Flow Control)
由3.2小节的描述可知,LL Data PDU的Header中,有NESN(Next Expected Sequence Number)和SN(Sequence Number)两个标记,利用它们,可以很轻松的在Link Layer实现应答、重传、流控等机制。
为了实现这些功能,Link Layer会为每个连接创建两个变量,transmitSeqNum和nextExpectedSeqNum(为了和packet的SN/NESN bit区分,我们将它们简称为sn和nesn),并在连接建立的时候,它们都被初始化为0。
sn用于标识本地设备(Link Layer)发送出去的packets。
nesn是对端设备(Link Layer)用来应答本地设备发送的packet,或者请求本地设备重发packet。
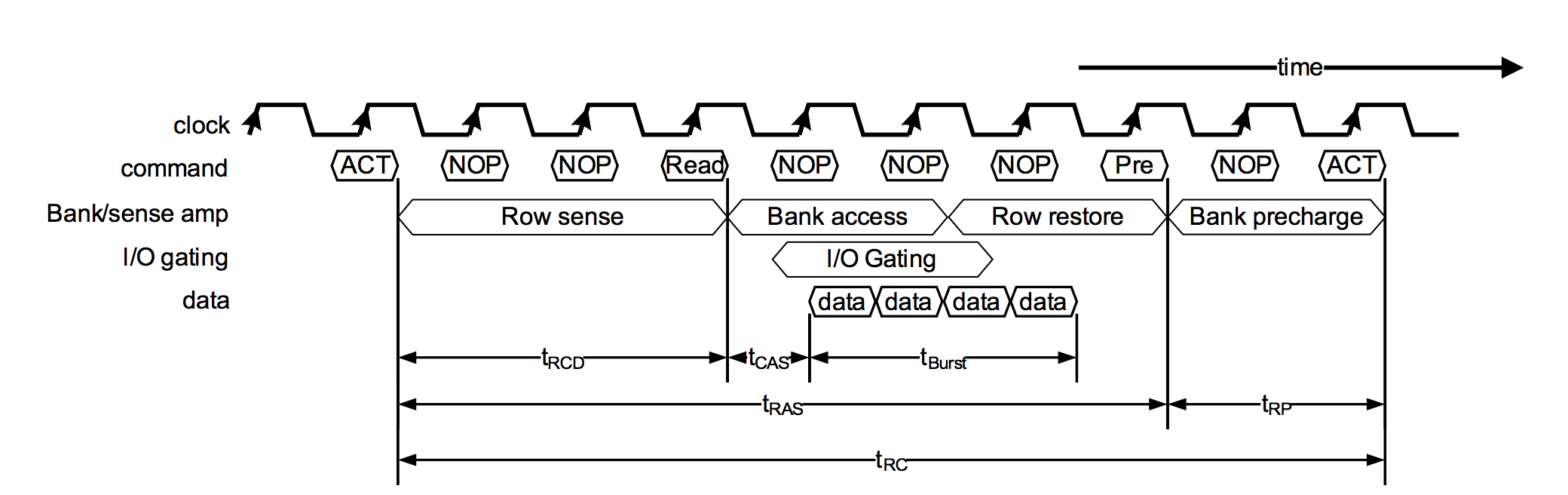
Link Layer在收发packet时,会遵循如下的原则(可结合下面图片4理解):
注5:下面图片4是从“BLUETOOTH SPECIFICATION Version 4.2 [Vol 6, Part B]”中截的一张图,不过spec中画的有问题,我用红色字体改正了。另外,这个图片非常有歧义、难以理解,我会在下面解释。
1)无论是Master还是Slave,发送packet的时候,都会将当前的sn和nesn copy到packet的SN和NESN bit中。
2)无论是Master还是Slave,当接收到一个packet的时候,会将该packet的NESN bit和本地的sn比较:如果相同,说明该packet是对端设备发来的NAK packet(请求重发),则需要将旧的packet重新发送出去;如果不同,说明是对端设备发来的ACK packet(数据被正确接收),则需要将本地的sn加1,接着发送新的packet。
a)以上过程可参考下面图片4中的左边部分。
b)本地的sn,代表本地设备已经发送出去的packet,而packet中的NESN bit,代表对端设备期望本地设备发送的packet。如果二者相同,说明对方期望下次发送的packet,和我们已经发送的packet相同,因此是NAK信号,要求重发。如果二者不同,说明对方设备期望发送一个新的packet,也说明我们上次发送的packet已经成功接收,因此可以将本地的sn加1了。
3)无论是Master还是Slave,当接收到一个packet的时候,会将该packet的SN bit和本地的nesn比较:如果相同,则说明是一个新的packet,接收即可,同时将本地的nesn加1;如果不同,则说明是一个旧的packet,什么都不需要处理。
a)以上过程可参考下面图片4中的右边部分。
b)packet中的SN bit,代表对端设备正在发送的packet,而本地设备的nesn,代表本地设备期望对端设备发送的packet。如果二者相同,则说明是一个期望的packet(新的),就可以收下该packet,并将期望值加1(nesn加1)。如果二者不同,说明不是本地设备期望的packet,什么都不做就可以了。
4)上面2)和3)两个步骤,是相互独立的,因此一个NAK packet,也可能携带新的数据,反之亦然。
5)当一个设备无法接收新的packet的时候(例如RX buffer已满),它可以采取不增加nesn的方式,发送NAK packet。对端设备收到该类型的packet之后,会发送旧的packet(图片4左边部分的“TX old data, sn”分支)。该设备收到这样旧的packet的时候,不会做任何处理(图片4右边部分的“Ignore RX data”分支)。这就是Link Layer的流控机制(Flow control)

图片4 BLE应答和流控机制
4. HCI
HCI(Host Control Interface)的功能就简单多了,就是要封装Link Layer所提供的功能,包括两类。
1)连接的建立、关闭、参数设置、管理等,这一类是通过HCI command/event(其格式可参考“蓝牙协议分析(5)_BLE广播通信相关的技术分析”中的介绍)完成的,包括:
LE Create Connection Command,建立连接的命令,需要提供连接有关的参数,包括connInterval(Conn_Interval_Min和Conn_Interval_Max)、connSlaveLatency(Conn_Latency)和connSupervisionTimeout(Supervision_Timeout)。
LE Create Connection Cancel Command,取消或者断开连接。
LE Connection Update Command,更新连接参数,包括connInterval(Conn_Interval_Min和Conn_Interval_Max)、connSlaveLatency(Conn_Latency)和connSupervisionTimeout(Supervision_Timeout)。
LE Set Host Channel Classification Command,配置Channel map。
LE Read Channel Map Command,读取Channel map。
等等。
有关这些命令的具体描述,可参考“BLUETOOTH SPECIFICATION Version 4.2 [Vol 2, Part E] Host Controller Interface Functional Specification”。
2)对ACL data的封装和转发,不再详细说明。
6. GAP
GAP(Generic Access Profile)的主要功能,是定义BLE设备所具备的能力,以实现互联互通的功能。
对BEL基于连接的通信来说,GAP定义了4种连接有关的模式(不同的产品形态,可以选择是否支持这些模式,具体可参考“BLUETOOTH SPECIFICATION Version 4.2 [Vol 3, Part C] 9.3 CONNECTION MODES AND PROCEDURES”):
Non-connectable mode,不可被连接。
Directed connectable mode,可以被“直连”(在知道对方蓝牙地址的情况下的快速连接)。
Undirected connectable mode,可以被“盲连”(不知道对方蓝牙地址)。
Auto connection establishment procedure,可以被自动连接(不需要host干预)。
相应地,GAP定义了5中和这些模式有关的过程(不同的产品形态,可以选择是否支持这些过程):
General connection establishment procedure,通用的连接建立过程,搜索、发现、连接,都需要Host参与。
Selective connection establishment procedure,有选择的连接建立过程,Host需要告诉Controller,自己只希望于特定的设备建立连接。
Direct Connection Establishment Procedure,直接和某一个已知设备建立连接(对方也知道我们)。
Connection Parameter Update Procedure,连接参数的更新过程。
Terminate Connection Procedure,断开连接。
这些mode和procedure的具体描述,可参考蓝牙spec[1]。
7. 参考文档
[1] Core_v4.2.pdf
原创文章,转发请注明出处。蜗窝科技,www.wowotech.net。



























")